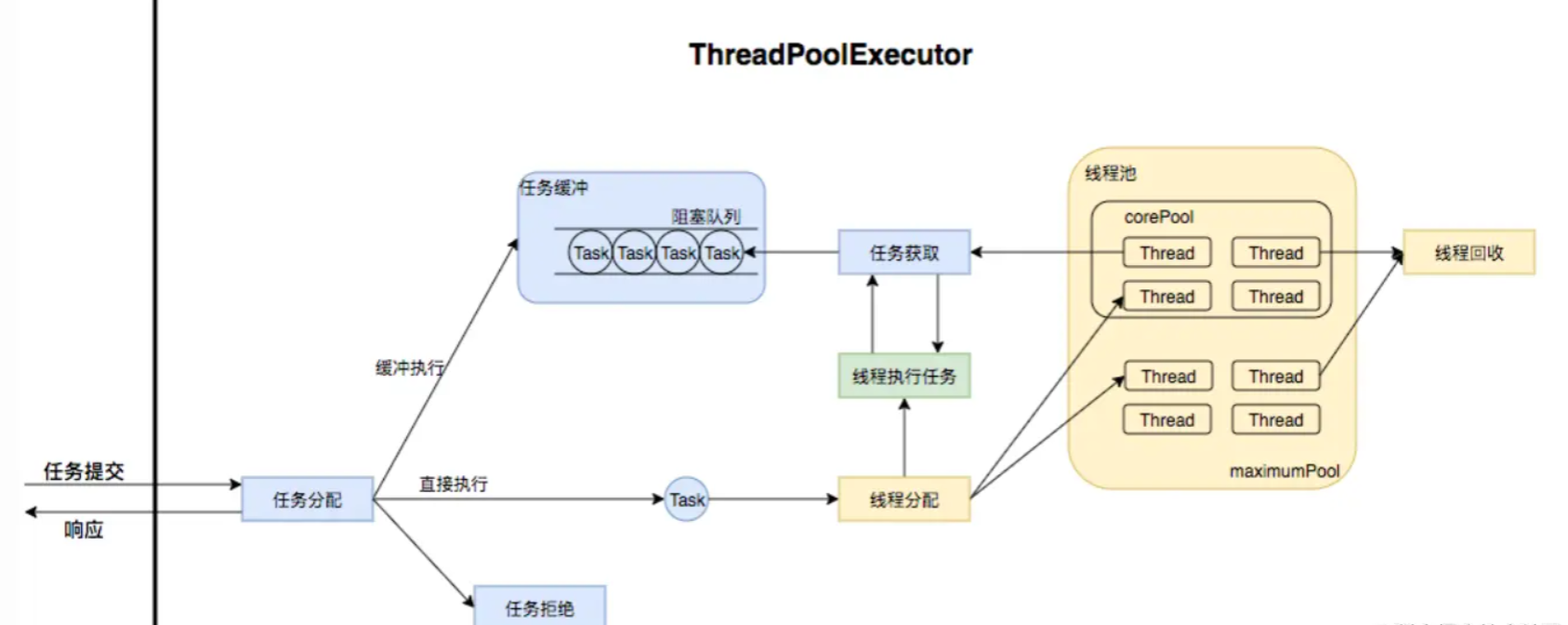
使用 我们 JDK 中提供了一些封装好的线程池提供直接使用,比如
newFixedThreadPool :返回一个核心线程数为 nThreads 的线程池
1 2 3 4 public static ExecutorService new FixedThreadPool (int nThreads) {return new ThreadPoolExecutor (nThreads, nThreads, 0 L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>());
newSingleThreadExecutor :返回一个核心线程数为 1 的线程池
1 2 3 4 public static ExecutorService new SingleThreadExecutor () {return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0 L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue <Runnable>()));
1 2 3 public static ExecutorService new CachedThreadPool () {return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60 L, TimeUnit.SECONDS, new SynchronousQueue <Runnable>());
通过上面 JDK 提供的我们可以发现一个共识,他们其实都是调用了 ThreadPoolExecutor 的构造方法来进行线程池的创建
阿里巴巴Java开发手册中明确指出,『不允许』使用Executors创建线程池 ,因为可能会出现OOM的问题(提问:出现OOM应该怎么排查问题?),所以,我们在生产中,一般使用 ThreadPoolExecutor 的构造方法自定义去创建线程池,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class ThreadPoolTest public static void main(String [] args) {new ThreadPoolExecutor (2 , 5 , 200 , new LinkedBlockingQueue <>(), new ThreadPoolExecutor .AbortPolicy() for (int i = 0 ; i < 10 ; i++) {new MyTask ();class MyTask implements Runnable public void run() {"我被执行了...." );
源码 执行流程:
初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler ) this (corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,handler );public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler ) if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0 )throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null )throw new NullPointerException();this .corePoolSize = corePoolSize;this .maximumPoolSize = maximumPoolSize;this .workQueue = workQueue;this .keepAliveTime = unit.toNanos(keepAliveTime);this .threadFactory = threadFactory;this .handler = handler ;
我们上面初始化的过程主要对入参做了一些校验,然后将方法的入参赋予给成员变量
拒绝策略
简单粗暴,直接抛出异常
1 2 3 4 5 6 public static class AbortPolicy implements RejectedExecutionHandler public AbortPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());
当前拒绝策略会在线程池无法处理任务时,将任务交给调用者处理(适合用于处理比较重要的任务,不可丢失,但是实习的时候进行CR的时候听说可能会阻塞主线程)
1 2 3 4 5 6 7 8 9 public static class CallerRunsPolicy implements RejectedExecutionHandler public CallerRunsPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) if (!e.isShutdown()) {
如果当前的阻塞队列满了,弹出时间最久的
1 2 3 4 5 6 7 8 9 10 11 public static class DiscardOldestPolicy implements RejectedExecutionHandler public DiscardOldestPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e) if (!e.isShutdown()) {
简单粗暴,不做任何操作
1 2 3 4 5 6 public static class DiscardPolicy implements RejectedExecutionHandler public DiscardPolicy () public void rejectedExecution (Runnable r, ThreadPoolExecutor e)
1 2 3 4 5 6 7 public static class MyRejectedExecution implements RejectedExecutionHandler {@Override public void rejectedExecution (Runnable r, ThreadPoolExecutor executor ) {System .out .println ("这是我自己的拒绝策略" );
其余变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private final AtomicInteger ctl = new AtomicInteger (ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;private static int runStateOf (int c) { return c & ~CAPACITY; }private static int workerCountOf (int c) { return c & CAPACITY; }
线程池的状态变化流程图
线程池的execute方法
Step1:当前的线程池个数低于核心线程数,直接添加核心线程即可
Step2:当前的线程池个数大于核心线程数,将任务添加至阻塞队列中
Step3:如果添加阻塞队列失败,则需要添加非核心线程数处理任务
Step4:如果添加非核心线程数失败(满了),执行拒绝策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public void execute(Runnable command) {// 如果当前传过来的任务是null,直接抛出异常即可if (command == null)// 获取当前的数据值// ==========================线程池第一阶段:启动核心线程数开始==================================================// Step1:获取ctl低29 位的数值,与我们的核心线程数相比if (workerCountOf(c) < corePoolSize) {// Step2:添加一个核心线程if (addWorker(command, true)){// 更新一下当前值// ==========================线程池第一阶段:启动核心线程数结束==================================================// 如果走到下面会有两种情况:// 1 、核心线程数满了,需要往阻塞队列里面扔任务// 2 、核心线程数满了,阻塞队列也满了,执行拒绝策略// ==========================线程池第二阶段:任务放至阻塞队列开始==================================================// 判断当前的状态是不是Running的状态(RUNNING可以处理任务,并且处理阻塞队列中的任务)// 如果是Running的状态,则可以将任务放至阻塞队列中// 这里如果放阻塞队列失败了,证明阻塞队列满了if (isRunning(c) && workQueue.offer(command)) {// 再次更新数值// 再次校验当前的线程池状态是不是Running// 如果线程池状态不是Running的话,需要删除掉刚刚放的任务if (!isRunning(recheck) && remove(command)){// 执行拒绝策略// 如果到这里,说明上面阻塞队列中已经有数据了// 如果线程池的个数为0 的话,需要创建一个非核心工作线程去执行该任务// 不能让人家堵塞着else if (workerCountOf(recheck) == 0 ){// ==========================线程池第二阶段:任务放至阻塞队列结束==================================================// 如果走到这里的逻辑,证明上面的逻辑没走通,有以下两种情况:// 1 、线程池的状态不是Running// 1.1 如果是这种情况,下面的添加非核心工作线程失败执行拒绝策略,但这个并不是这个逻辑的重点// 2 、阻塞队列添加任务失败(阻塞队列满了)// 2.1 这种情况才是我们需要关心的// 2.2 阻塞队列满了,添加非核心工作线程// 2.3 若添加非核心工作线程失败,证明已经到达maximumPoolSize的限制,执行拒绝策略// ==========================线程池第三阶段:启动非核心线程数开始==================================================// 添加一个非核心工作线程else if (!addWorker(command, false))// 工作队列中添加任务失败,执行拒绝策略// ==========================线程池第三阶段:启动非核心线程数结束==================================================
线程池的addWorker方法 addWorker`方法也是一个很关键的方法, 添加线程到线程池,返回 true 表示创建 Worker 成功,且启动线程。
校验
校验当前线程池的状态
校验当前线程池工作线程的个数(核心线程数、最大工作线程数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 private boolean addWorker(Runnable firstTask, boolean core) {// 这里主要是为了结束整个循环for (;;) {// 获取当前线程池的数值(ctl)// runStateOf:基于&运算的特点,保证只会拿到ctl高三位的值// ==========================线程池状态判断=============================================================// rs >= SHUTDOWN:代表当前线程池状态为:SHUTDOWN、STOP、TIDYING、TERMINATED,线程池状态异常// 但这里SHUTDOWN状态稍许不同(不会接收新任务,正在处理的任务正常进行,阻塞队列的任务也会做完)// 如果当前的状态是SHUTDOWN状态并且阻塞队列任务不为空且新任务为空// 需要新起一个非核心工作线程去执行任务// 如果不是前面的,直接返回false即可if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty())){// ==========================工作线程个数判断==========================================================for (;;) {// 获取当前线程池中线程的个数// 1 、如果线程池线程的个数是否超过了工作线程的最大个数// 2 、core=true(核心线程)=false(工作线程)// 2.1 根据当前core判断创建的是核心线程数(corePoolSize)还是非核心线程数(maximumPoolSize)if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)){// 尝试将线程池线程加一if (compareAndIncrementWorkerCount(c)){// CAS成功后,直接退出外层循环,代表可以执行添加工作线程操作了。break retry;// 获取当前线程池的数值(ctl)// 获取当前线程池的状态// 判断当前线程池的状态等不等于我们上面的rs// 我们线程池的状态被人更改了,需要重新跑整个for 循环判断逻辑if (runStateOf(c) != rs){continue retry;// 省略下面的代码
添加线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 boolean workerStarted = false ;boolean workerAdded = false ;Worker w = null ;try {new Worker (firstTask);final Thread t = w.thread;if (t != null ) {final ReentrantLock mainLock = this .mainLock;try {int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||null )) {if (t.isAlive()) throw new IllegalThreadStateException ();int s = workers.size();if (s > largestPoolSize)true ;finally {if (workerAdded) {true ;finally {if (! workerStarted)return workerStarted;private void addWorkerFailed (Worker w) {final ReentrantLock mainLock = this .mainLock;try {if (w != null )finally {
这里注意一个点,SHUTDOWN 状态也能添加线程,但是要求新加的 Woker 没有 firstTask,而且当前 queue 不为空,所以创建一个线程来帮助线程池执行队列中的任务。
这里为什么要加全局锁?因为下面的操作是添加worker,但是万一其他调用了shotdown()或者shotdownNow()方法,那我到底是添加还是不添加?这是一个纠结的事情,当我们点开shotdown()或者shotdownNow()方法时,会发现也有一个全局lock锁,所以加锁的原因是不想添加worker与关闭线程池冲突!
线程池的 worker 源码 Woker类是ThreadPoolExecutor类的内部类,见明知意,它是承担了一个“工人”干活,也就是工作线程的责任。
每个 Worker 对象有一个初始任务,启动 Worker 时优先执行,这也是造成线程池不公平的原因。Worker 继承自 AQS,本身具有锁的特性,采用独占锁模式,state = 0 表示未被占用,> 0 表示被占用,< 0 表示初始状态不能被抢锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private final class Worker extends AbstractQueuedSynchronizer implements Runnable {final Thread thread; volatile long completedTasks; 1 );this .firstTask = firstTask;this .thread = getThreadFactory().newThread(this );protected boolean tryAcquire (int unused) {if (compareAndSetState(0 , 1 )) {return true ;return false ;protected boolean tryRelease (int unused) {null );0 );return true ;
1 2 3 4 5 public void run ()this );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 final void runWorker(Worker w) {task = w.firstTask;null ;boolean completedAbruptly = true ;try {while (task != null || (task = getTask()) != null ) {if ((runStateAtLeast(ctl.get(), STOP) ||try {task );null ;try {task .run();catch (RuntimeException x) {throw x;catch (Error x) {throw x;catch (Throwable x) {throw new Error(x);finally {task , thrown);finally {task = null ;false ;finally {
processWorkerExit()工作线程退出方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 private void processWorkerExit (Worker w, boolean completedAbruptly) {if (completedAbruptly) decrementWorkerCount ();final ReentrantLock mainLock = this .mainLock ;lock ();try {completedTasks ;remove (w);finally {unlock (); tryTerminate ();int c = ctl.get ();if (runStateLessThan (c, STOP)) {if (!completedAbruptly) {int min = allowCoreThreadTimeOut ? 0 : corePoolSize;if (min == 0 && !workQueue.isEmpty ())min = 1 ;if (workerCountOf (c) >= min )return ;addWorker (null , false );
线程复用的原理 在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对 Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停的检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式将只使用固定的线程就将所有任务的 run 方法串联起来。
其实就是runWorker()方法
省略掉部分和复用无关的代码之后,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 final void runWorker(Worker w) {task = w.firstTask;null ;boolean completedAbruptly = true ;try {while (task != null || (task = getTask()) != null ) {task .run();false ;finally {
可以看到,实现线程复用的逻辑主要在一个不停循环的 while 循环体中。
通过获取 Worker 的 firstTask 或者通过 getTask 方法从 workQueue 中获取待执行的任务
直接通过 task.run() 来执行具体的任务(而不是新建线程)
在这里,我们找到了线程复用最终的实现,通过取 Worker 的 firstTask 或者 getTask 方法从 workQueue 中取出了新任务,并直接调用 Runnable 的 run 方法来执行任务,也就是如之前所说的,每个线程都始终在一个大循环中,反复获取任务,然后执行任务,从而实现了线程的复用。