Redis五大类型源码及底层实现
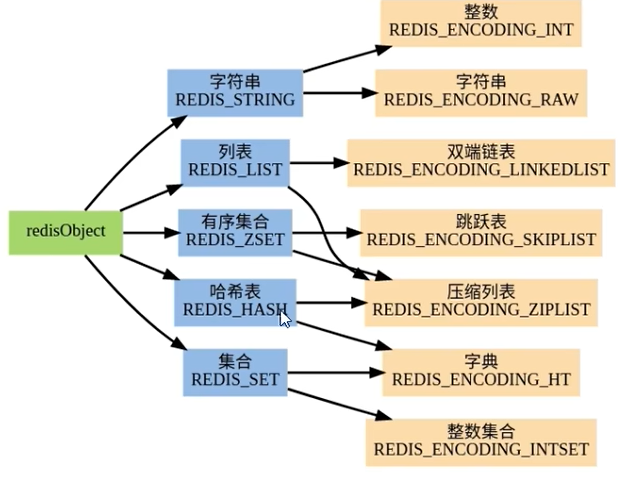
涉及到的底层实现总览
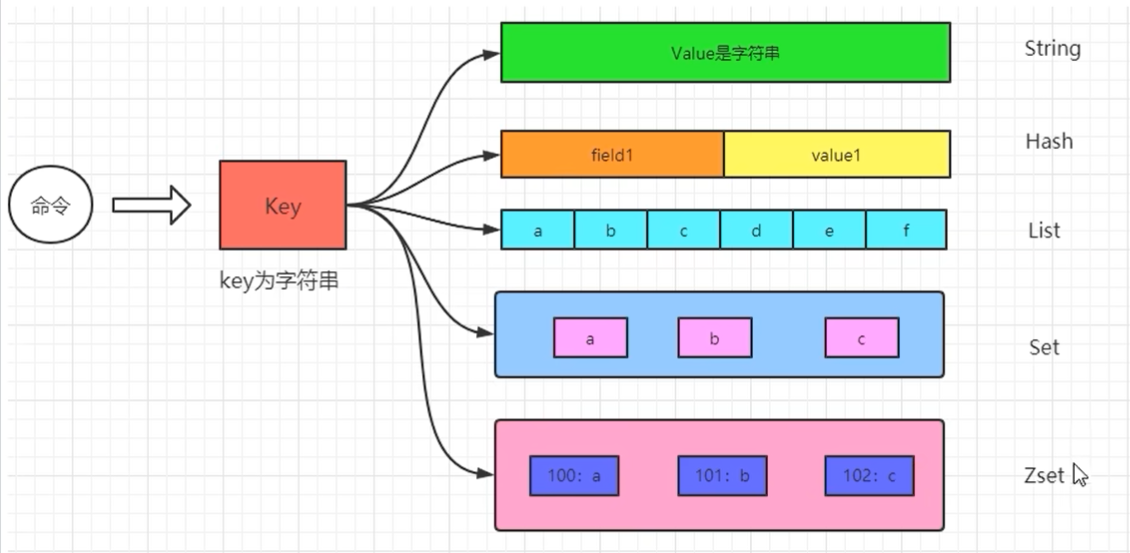
通过上图可知,key一般都是String类型的字符串对象,
而value类型则为redis对象(redisObject)
10大类型说明(粗分)
传统的5大类型
- String
- Hash
- list
- set
- zset
新介绍的5大类型
- bitmap —实质String
- hyperLoglog — 实质String
- GEO — 实质Zset
- Stream — 实质Stream
- BitField — 看具体key
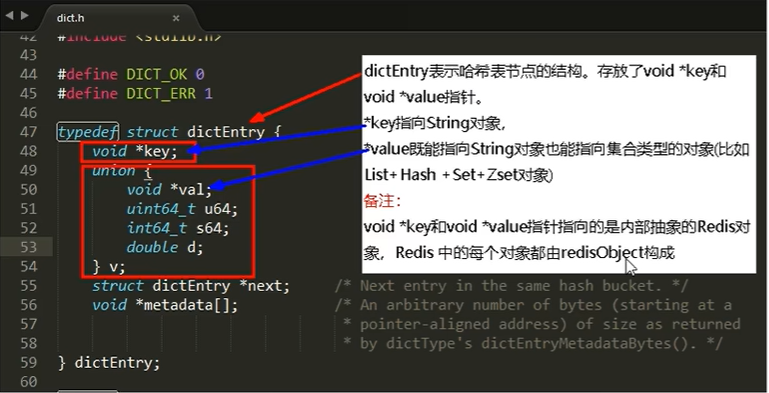
从dictEntry到redisObject
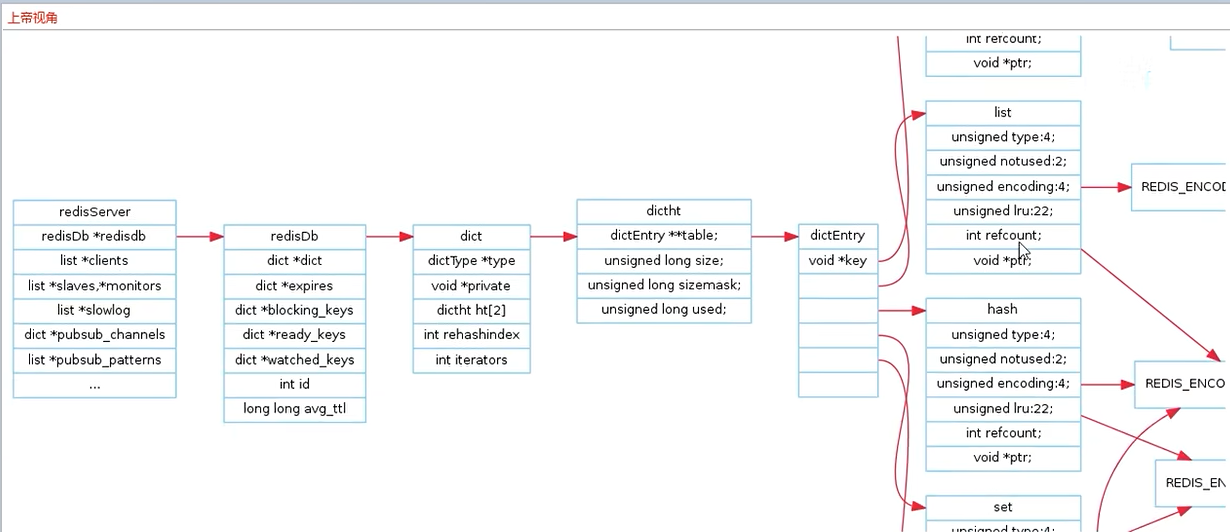
dictEntry表示哈希表结点的结构,存放了void* key和void* value指针
*key指向String对象,
*value既能指向String对象也能指向集合类型的对象(比如List+Hash+Set+Zset对象)23
redisObject
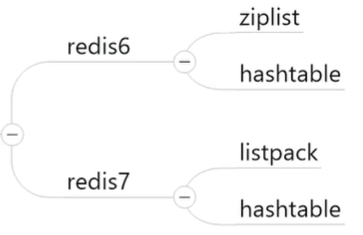
五大基本数据类型及底层实现(熟记)
但是Redis6与Redis7底层实现有所不同,所以两个版本都需要掌握
Redis6:

Redis7:

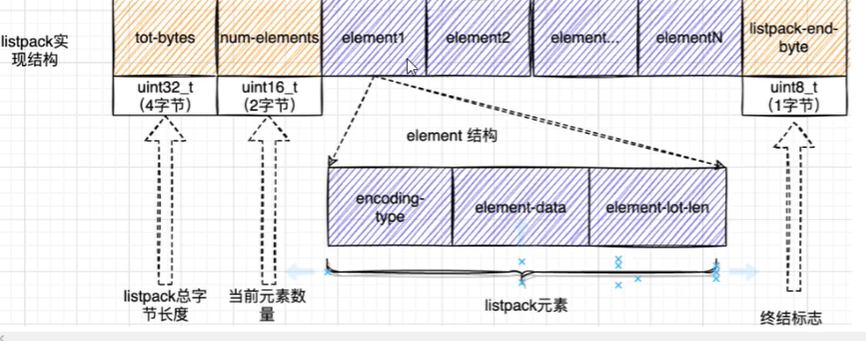
其中listpack代替了ziplist
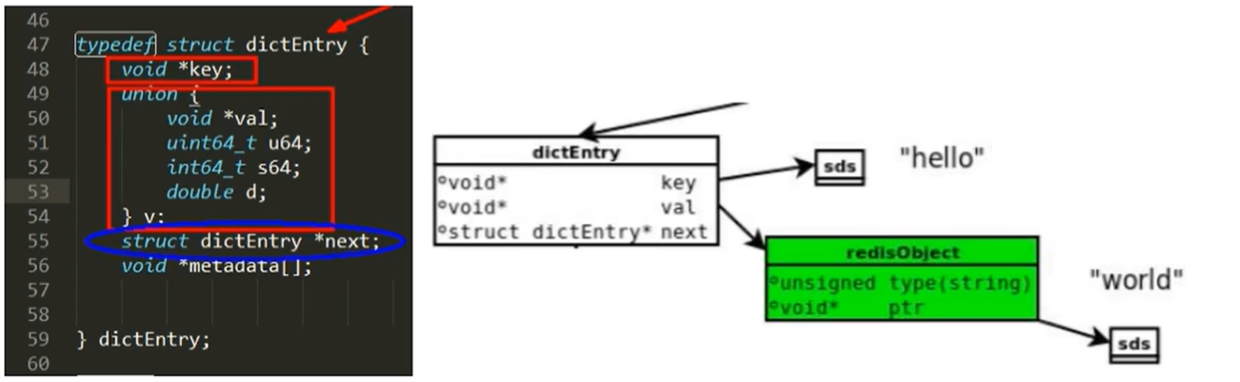
每个键值都会有一个dictEntry
我们以set hello word为例,因为Redis是KV键值对,每个键值对都会有一个dictEntry(源码位置:dict.h),里面指向了key和value的指针,next指向了下一个dictEntry。
key是字符串,但是Redis没有直接使用C的字符数组,而是存储在redis自定义的SDS中。
value既不是直接作为字符串存储,也不是直接存储在SDS中,而是存储在redisObject中。实际上五种常用的数据类型的任何一种都是通过redisObject来存储的
RedisObject的作用
为了便于操作,Redis采用redisObject结构来统一五种不同的数据类型,这样所有的数据类型就都可以以相同的形式在函数间传递而不用使用特定的类型结构。同时,为了redisObject中定义了type和encoding字段对不同的数据类型加以区别。简单地说,redisObject就是string、hash、list、set、zset地父类,可以在函数间传递时隐藏具体地类型信息,所以作者抽象了redisObject结构来达到同样的目的。

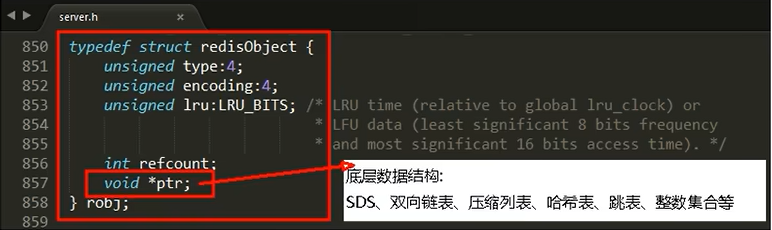
RedisObject各字段的含义
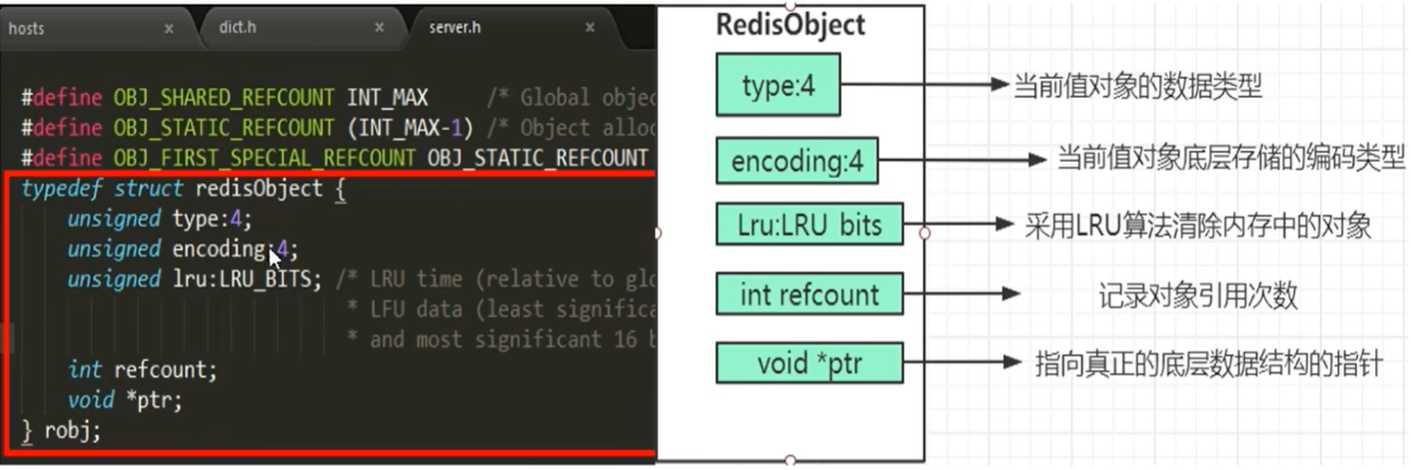
- 4位的type表示具体的数据类型
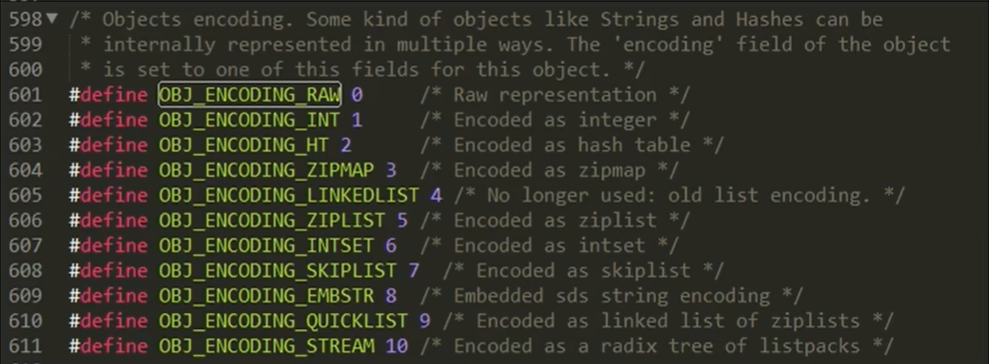
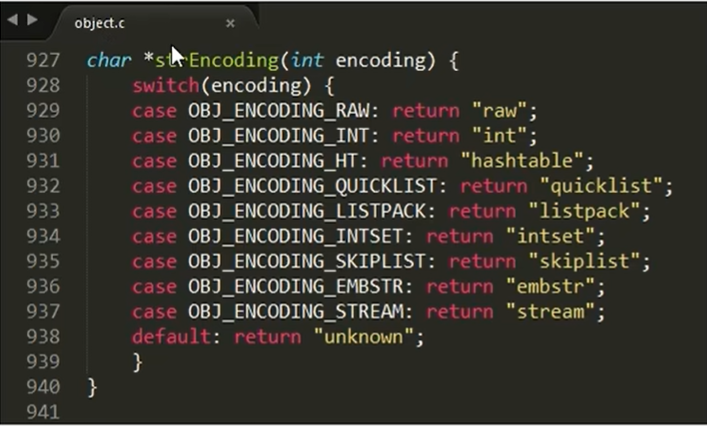
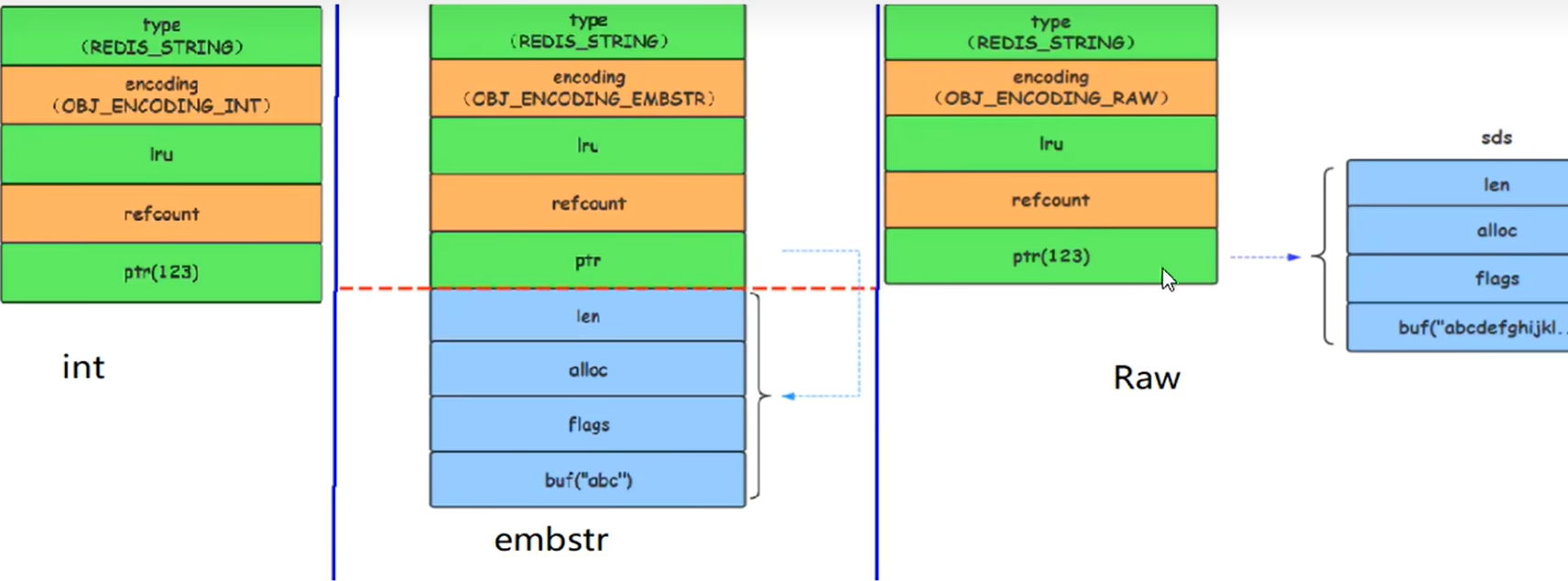
- 4位的encoding表示该类型的物理编码方式见下表,同一种数据类型可能有不同的编码方式(比如String就提供了3种:int、embstr、raw)
编码表:
- LRU字段表示当内存超限时采用LRU算法清楚内存中的对象
- refcount表示对象的引用计数
- ptr指针指向真正的底层数据结构的指针
物理编码-案例
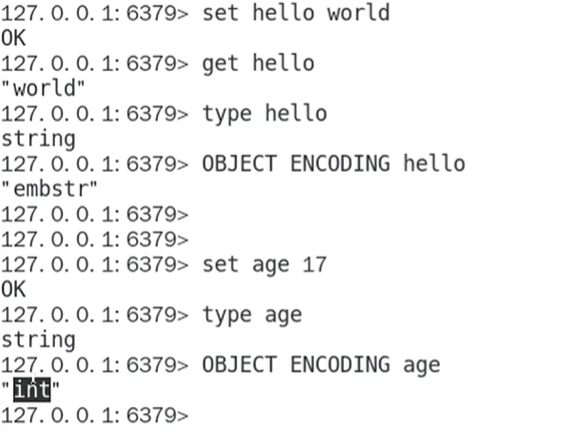
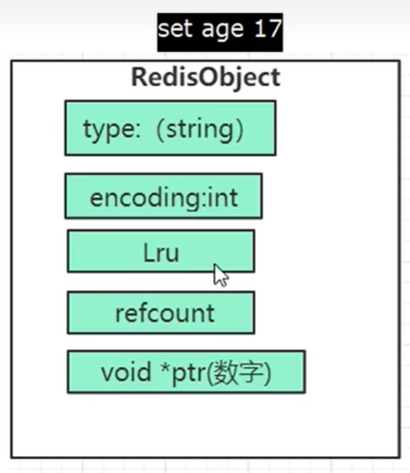
可以看到,hello和age同样是string类型,但是物理编码不同
各个类型的数据结构的编码映射和定义
string
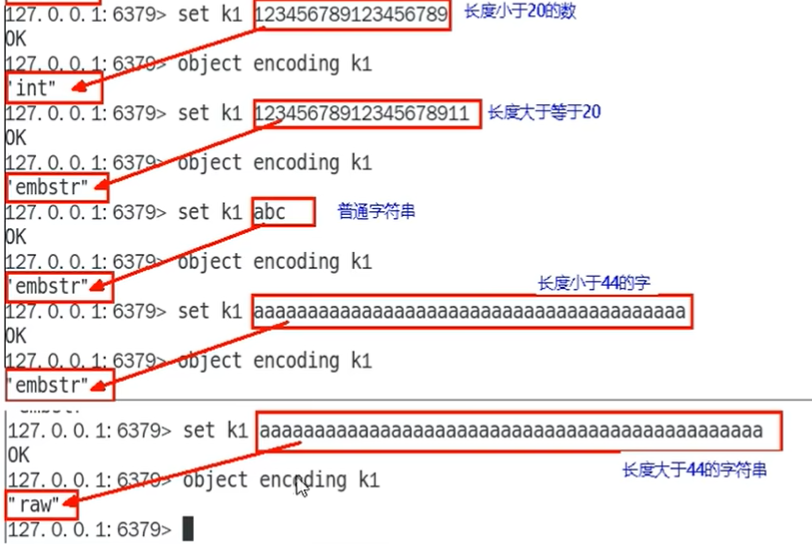
string类型有三种物理编码方式
- int
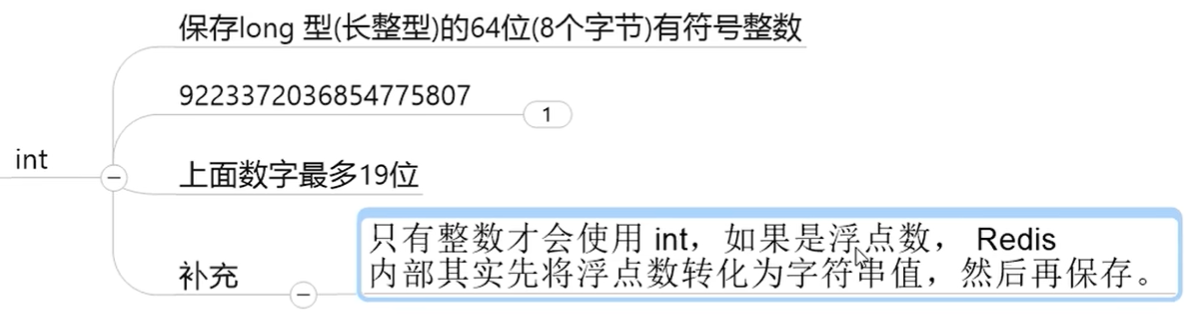
- embstr

- raw

测试案例
SDS(简单动态字符串)
Redis是由C语言编写的,那么为什么不用原生C语言的字符串(char数组)?
下面参考Redis设计与实现的一段话


下面就一起来探究
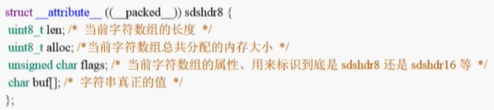
打开Redis源码包,sds.h,注意Redis6的SDS与Redis7的SDS不一样
通过对 buf 分配一些额外的空间,并使用 free 记录未使用空间的大小,sdshdr 可 以让执行追加操作所需的内存重分配次数大大减少
Redis3:

Redis7:
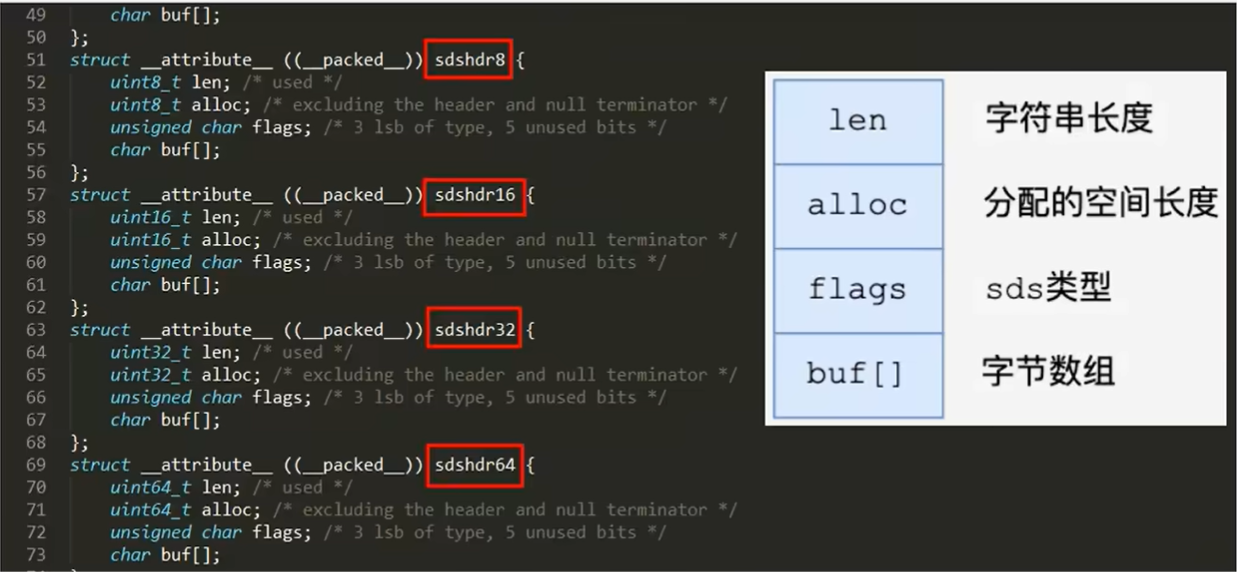
可以看到SDS有多种结构

都由len、alloc、flags、buf组成
好处:
- len表示SDS的长度,使我们在获取字符串长度的时候可以在O(1)的情况瞎拿到
- alloc可以用来计算free就是字符串已经分配未使用的空间,有了这个值就可以引入预分配空间的算法了,而不用去考虑内存分配的问题
综上所述

此外,在 Redis 中,客户端传入服务器的协议内容、aof 缓 存、返回给客户端的回复,等等,这些重要的内容都是由都是由 sds 类型来保存的。
三种物理编码区别

结构图:
Hash
两种编码格式,分为Redis6与Redis7
在Redis6中
hash-max-zip-entries:使用压缩列表保存时哈希集合的最大元素个数
hash-max-zip-value:使用压缩列表保存时哈希集合中单个元素的最大长度
Hash类型键的字段个数小于 hash-max-zip-entries 并且每个字段名和字段值的长度小于 hash-max-zip-value 时,Redis才会使用 OBJ_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会满足OBJ_ENCODING_HT的编码方式
OBJ_ENCODING_HT编码分析
OBJ_ENCODING_HT 这种编码方式内部才是真正的哈希表结构,或称为字典结构,其可以实现O(1)复杂度的读写操作,因此在Redis内部,从OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层层嵌套下去的,组织关系见下图:

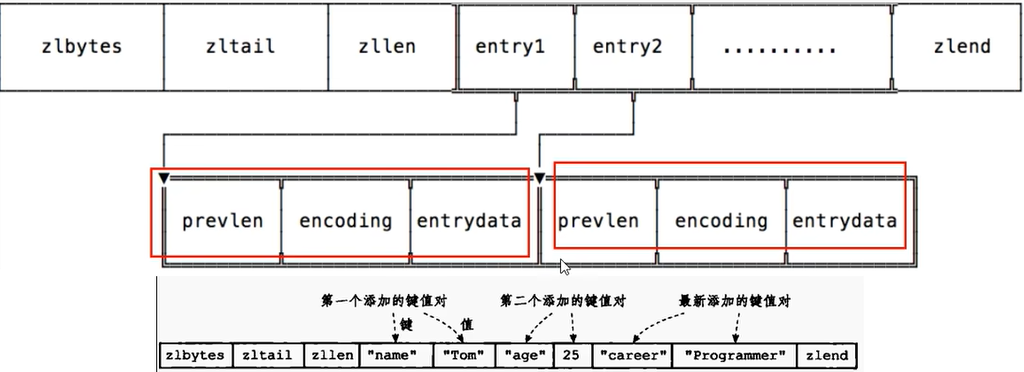
Ziplist
Ziplist压缩列表是一种紧凑编码格式,总体思想是多花时间换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,因此只会用于字段个数少,且字段值也较小的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
它是由连续内存块组成的顺序型数据结构,有点类似于数组
ziplist是一个经过特殊编码的双向链表,它不存储指向前一个链表节点prev和指向下一个链表节点next而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
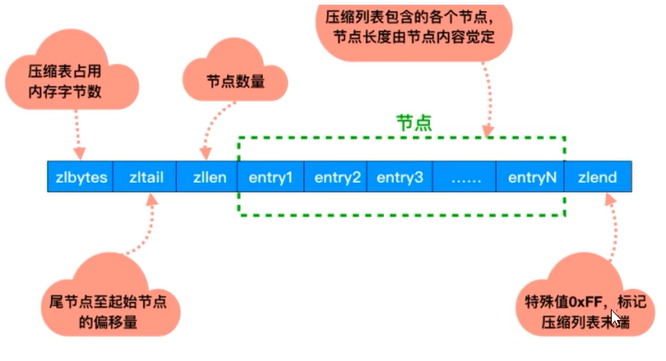

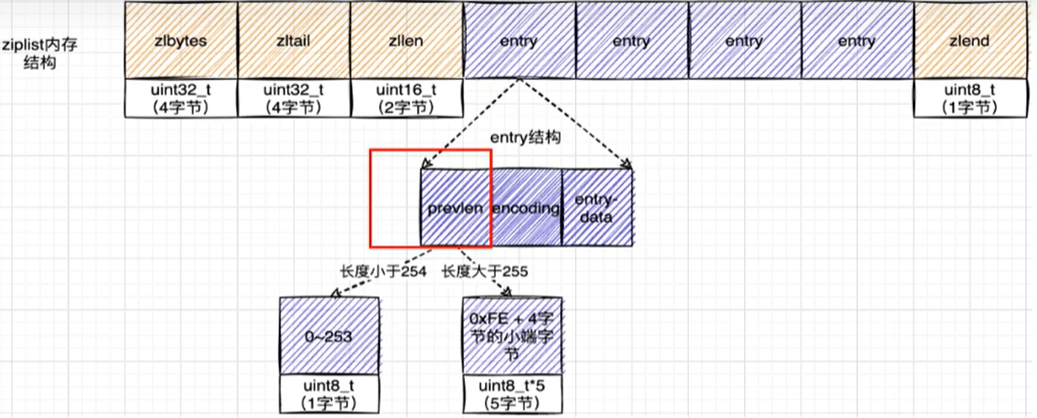
zlentry
那么存储数据的都是由**zlentry(压缩列表节点)**结构封装的
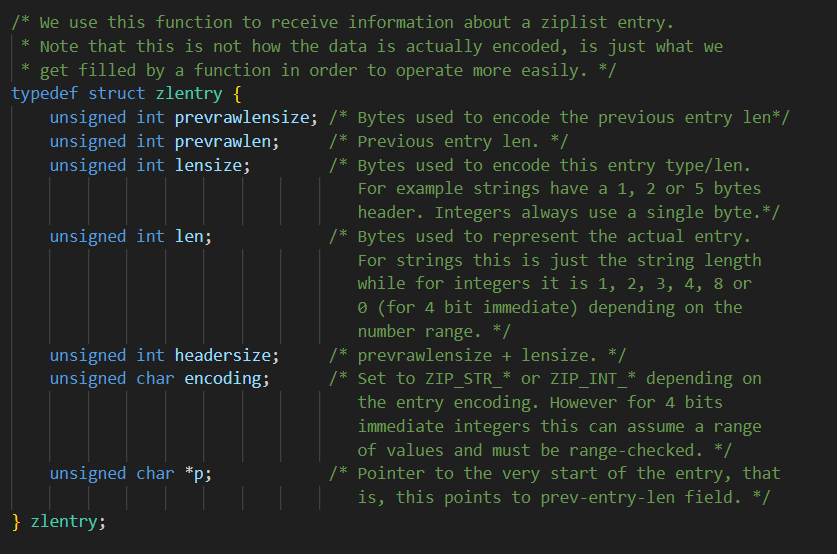

Ziplist存取情况
- prevlen:记录了前一个节点的长度
如果前一个节点的长度小于254字节,那么prelen属性需要用1字节空间保存这个长度值;
如果前一个节点的长度大于254字节,那么prelen属性需要用5字节空间保存这个长度值;
这就为连锁更新问题埋下了伏笔
- encoding:记录了当前节点实际数据以及长度
- data:记录了当前节点的实际数据
连锁更新

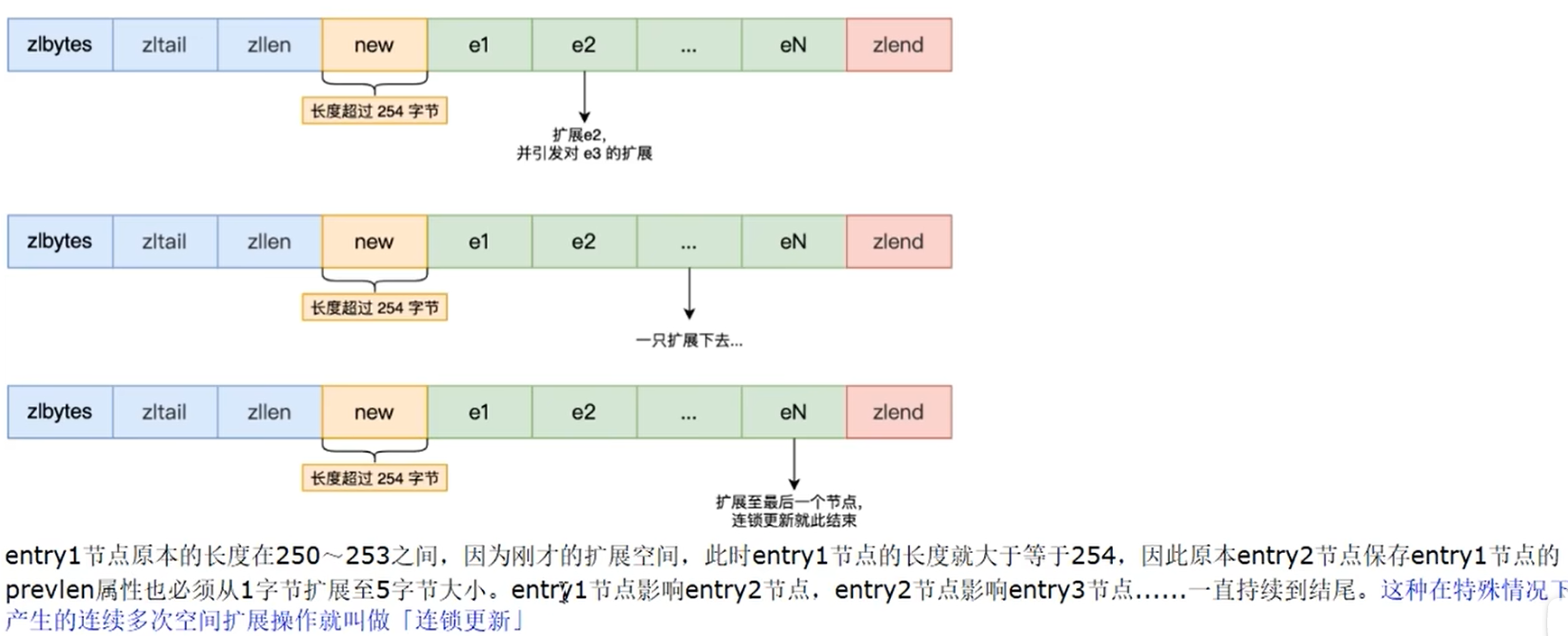
明明有链表了为什么出来一个压缩列表

Ziplist总结

Ziplist对比listpack
ziplist:
和ziplist列表项类似,listpack列表项也包含了远数据信息和数据本身,不过,为了避免ziplist引起的连锁更新问题,listpack中的每个列表项不再像ziplist列表项那样保存其前一个列表项的长度
listpack: