Redis大数据统计
先来一些常见问题

HyperLogLog


基本命令:
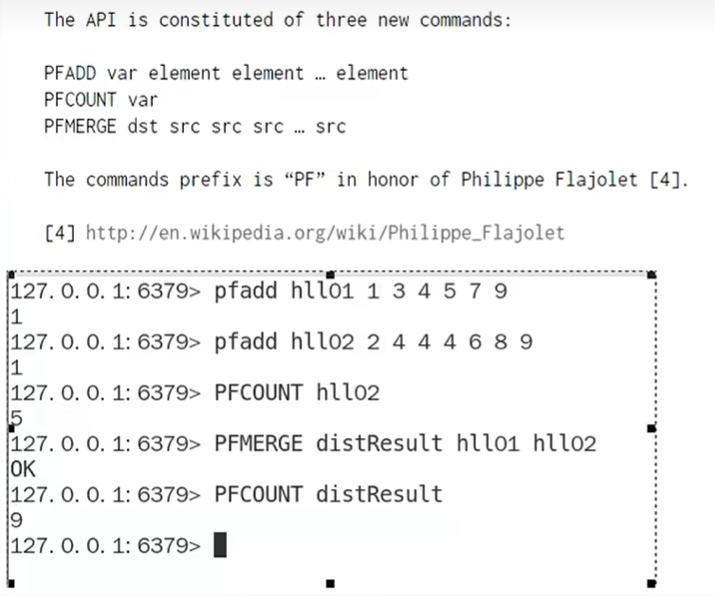
基数统计:

统计百万级的用bitmap还算可以接受,但是如果是亿级那么占用的内存会很高,所以应该使用HyperLogLog

HyperLogLog是牺牲了一定的准确度来换取空间,在大数据的情况下,一点误差是可以接受的。
HyperLogLog只是进行不重复的基数统计,不是集合也不保存数据,只纪录数量而不是具体内存,提供不精确的去重计数方案,误差率在0.81%左右

淘宝网站首页亿级UV的Redis统计方案
需求:
- UV的统计需要去重,一个用户一天内的多次访问只能算作一次
- 淘宝、天猫首页的UV,平均每天是1~1.5亿个左右
- 每天存1.5亿个IP,访问者来了后先去查是否存在,不存在加入
service:
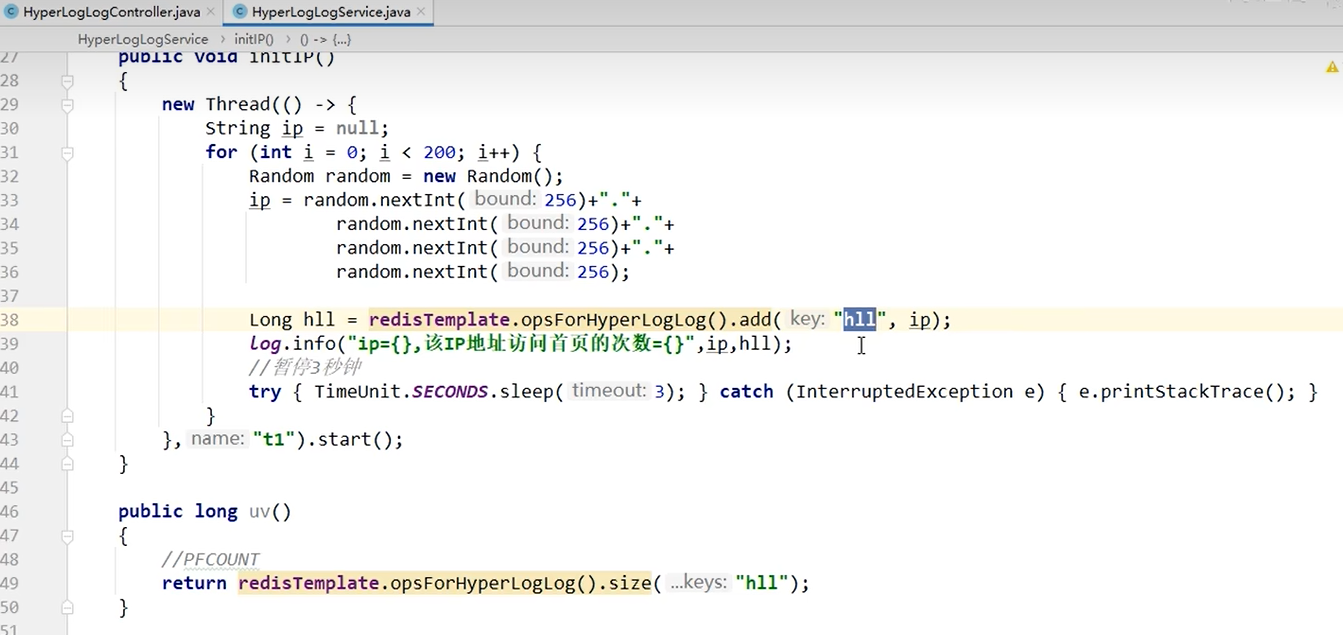
controller:
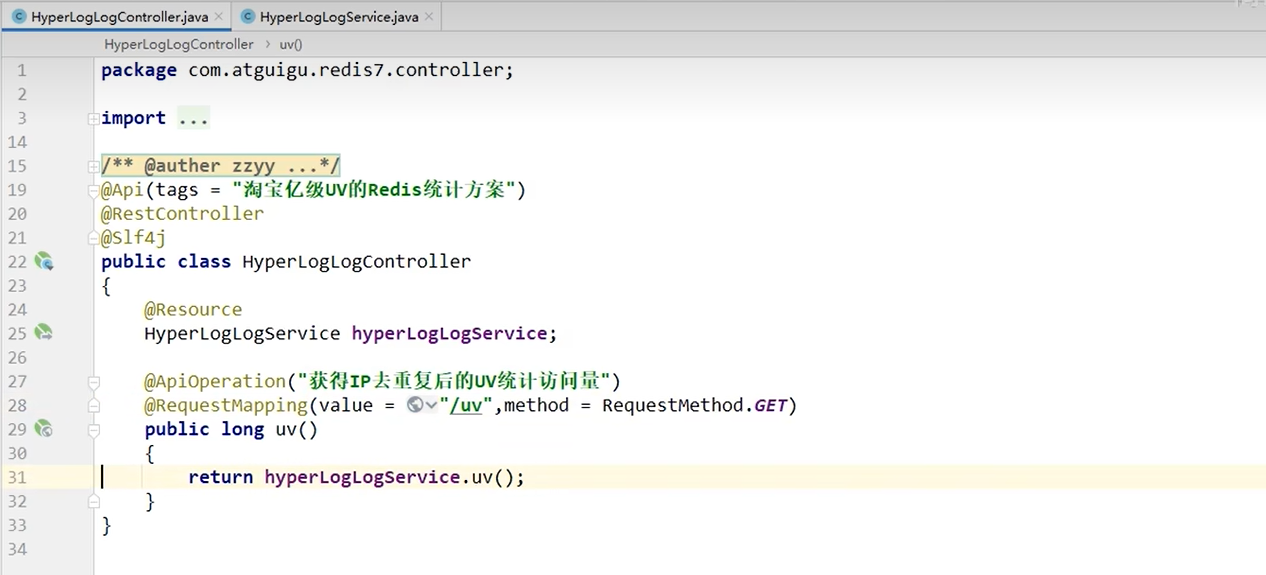
效果:
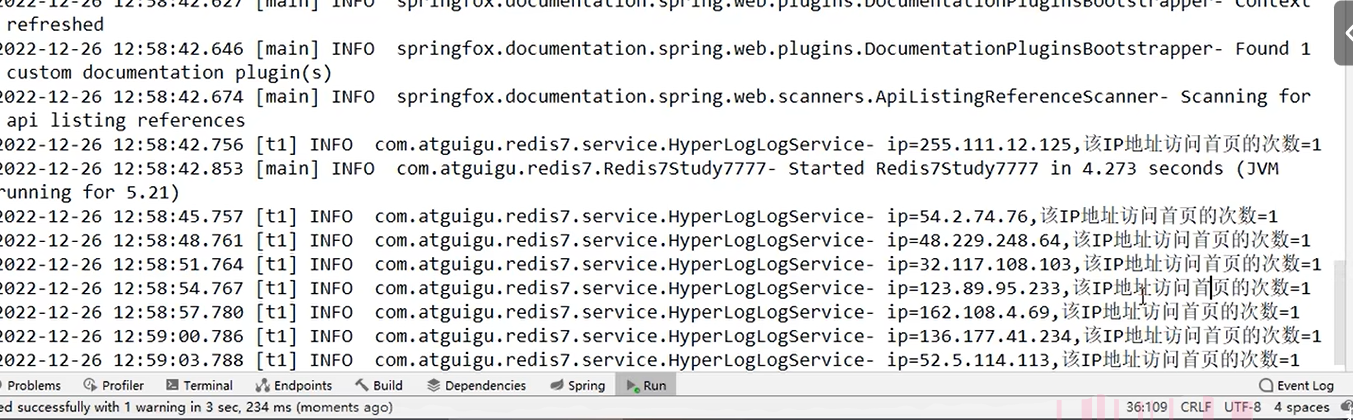
swagger点击一下:
还是很简单的
GEO
Redis大数据统计
http://example.com/2023/12/29/Redis大数据统计/